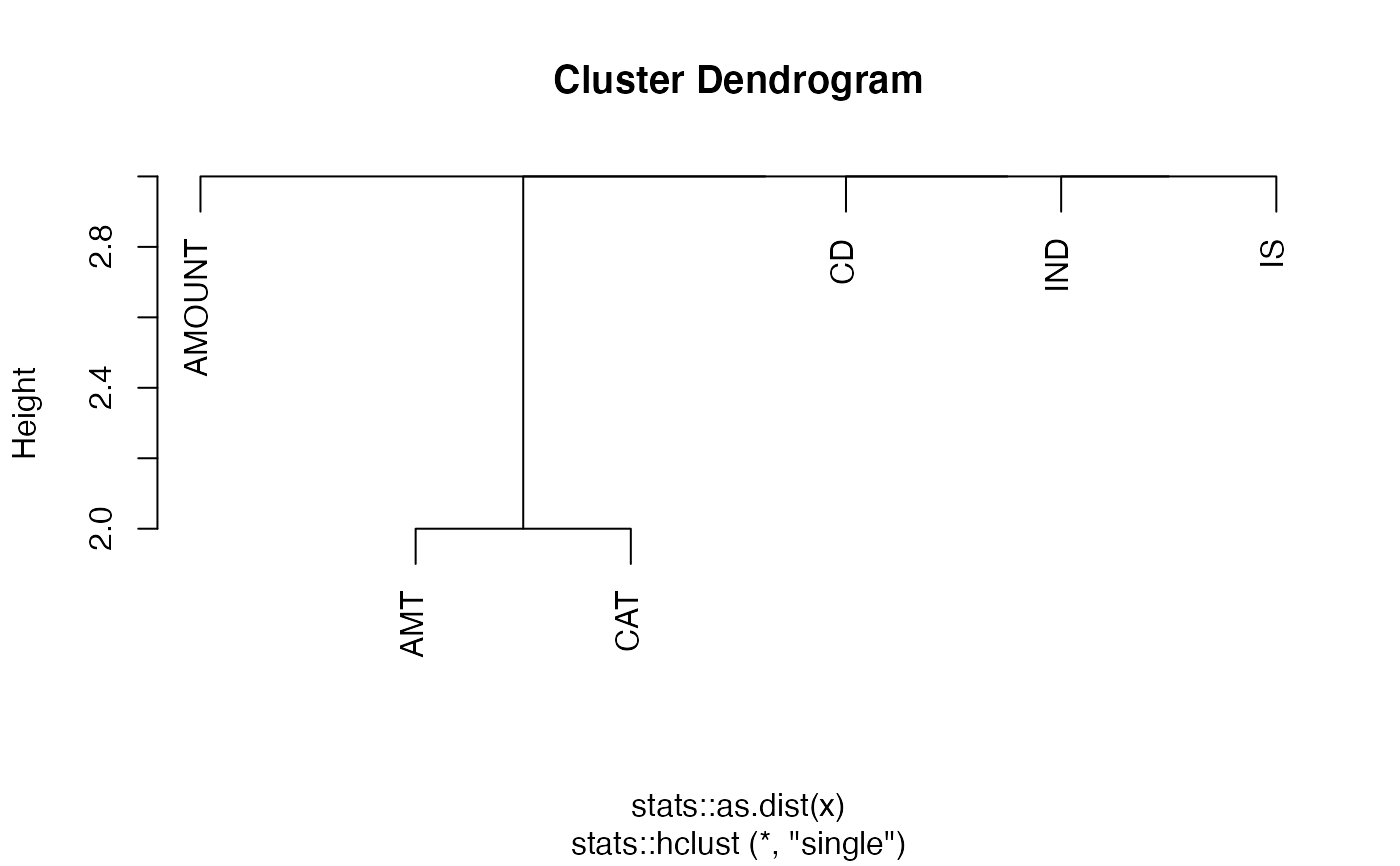
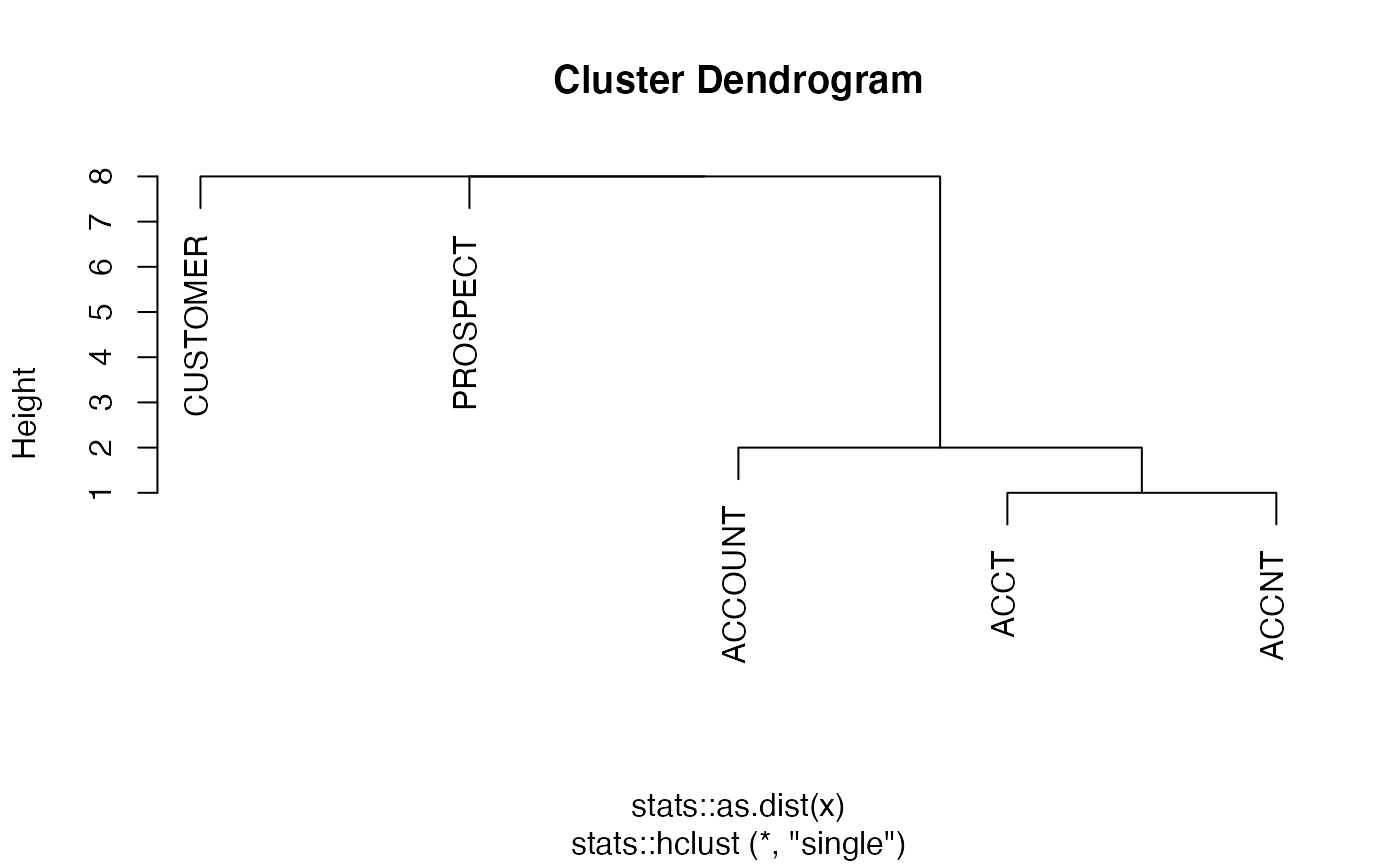
This function clusters name stubs by level to find potential
typos or similarities between names in the convo. Note that this is a rough,
exploratory tool but due to the complexity of human language and the variety of potential
stubs, it is not a foolproof method of determining duplication. This is illustrated in
the documentation's examples in which the clustering of level 1 stubs does not
highlight the desired relationship ("AMT" versus "AMOUNT") whereas it does highlight
the level 2 duplication ("ACCOUNT" versus "ACCT" versus "ACCNT").
cluster_convo( convo, adist_costs = c(ins = 1, del = 1, sub = 5), hclust_method = "single" )
Arguments
| convo | A |
|---|---|
| adist_costs | Relative costs of insertion, deletion, and substitution
passed to the |
| hclust_method | Agglomeration method passed to the |
Value
A list of hclust objects by level of the vocabulary
Details
The distance matrix is calculated using Levenshtein (edit) distance as implemented in
utils::adist. By default, the cost of insertion and deletion operations is set
lower to that of substitution since, in this case, we are more likely to wish to
identify redundancies caused by increasing levels of abbreviation. Thus, we prefer
to consider as more similiar those stubs which are pure subsets of other stubs. This
weighting can be controlled by the adist_costs argument.
The clustering is done using hierarchical clustering as implemented in stats::hclust().
By default, the agglomeration method is "single", but this can be altered with the argument
hclust_method.
Examples
convo <- list(c("IND", "IS", "AMT", "AMOUNT", "CAT", "CD"), c("ACCOUNT", "ACCT", "ACCNT", "PROSPECT", "CUSTOMER")) clusts <- cluster_convo(convo) plot(clusts[[1]])stubs <- parse_stubs(c("IND_ACCOUNT", "AMT_ACCT", "ID_ACCNT", "DT_LOGIN", "DT_ENROLL")) clusts <- cluster_convo(stubs, adist_costs = c(ins = 10, del = 10, sub = 1))