Define
Define stubs and optional metadata in YAML:
level1:
ID:
desc: Unique identifier
valid:
- col_vals_not_null()
- col_is_numeric()
- col_vals_between(1000, 99999)
IND:
desc: Binary indicator
valid:
- col_is_numeric()
- col_vals_in_set(c(0,1))
rename:
- when: SUM
then: 'N'
- when: AVG
then: P
AMT:
desc: Non-negative, summable quantity
valid:
- col_is_numeric()
- col_vals_gte(0)
VAL:
desc: Value
valid:
- col_is_numeric()
rename:
- when: AVG
then: VALAV
CAT:
desc: Category
valid:
- col_is_character()
CD:
desc: System-generated code
valid:
- col_is_character()
DT:
desc: Calendar date in YYYY-MM-DD format
valid:
- col_is_date()
level2:
A:
desc: Type A
C:
desc: Type C
D:
desc: Type D
level3:
"\\d{4}": []Read into R:
filepath <- system.file("", "ex-convo.yml", package = "convo")
convo <- read_convo(filepath)
print(convo)
#> Level 1
#> - ID
#> - IND
#> - AMT
#> - VAL
#> - CAT
#> - CD
#> - DT
#> Level 2
#> - A
#> - C
#> - D
#> Level 3
#> - \d{4}Check
Before using our convo to evaluate names, we may want to check that it itself follows good practices. There are a few exploratory tools to help us identify suboptimal aspects. To illustrate, let’s consider a slightly more problematic controlled vocabulary that what we read in above.
First, the pivot_convo() function can help us determine if any stubs are used in multiple levels, which could potentially cause confusion or misinterpretation. In the example below, we see that the stub “CAT” is used in level 1 to denote a categorical and in level 2 to denote the animal “CAT”.
convo_draft <- list(c("IND", "AMT", "CAT"), c("DOG", "CAT"))
pivot_convo(convo_draft)
#> $CAT
#> [1] 1 2We can also also cluster stubs and search for possible redundancy with the cluster_convo() function. Here, the level 1 stubs are mostly reasonable (but “IND” and “IS” might both be redundant and represent binary variables), but the level 2 stubs are highly redundant with “ACCOUNT”, “ACCT”, and “ACCNT” likely all representing the same concept.
convo_draft <- list(c("IND", "IS", "AMT", "AMOUNT", "CAT", "CD"),
c("ACCOUNT", "ACCT", "ACCNT", "PROSPECT", "CUSTOMER"))
clusts <- cluster_convo(convo_draft)
plot(clusts[[1]])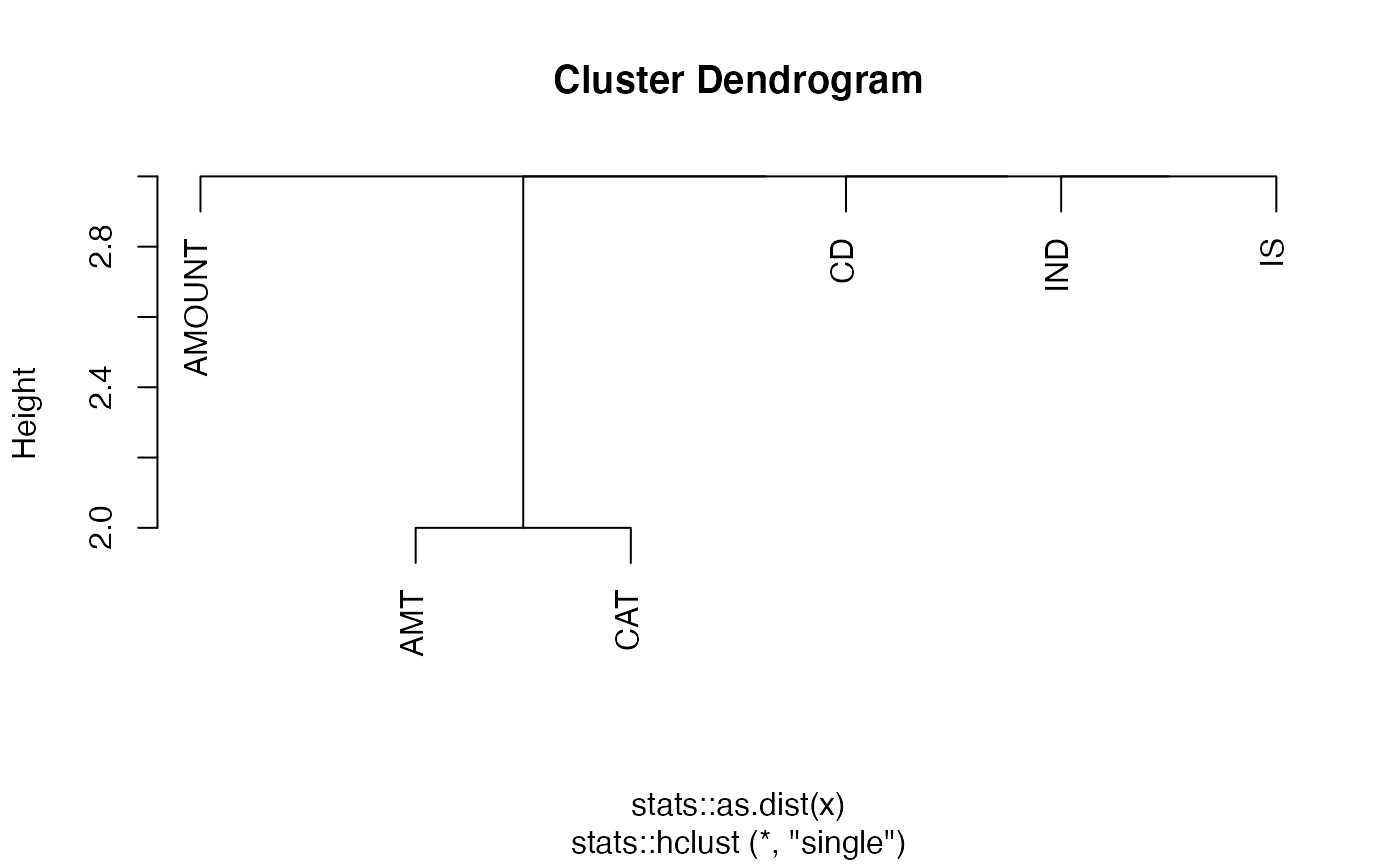
plot(clusts[[2]])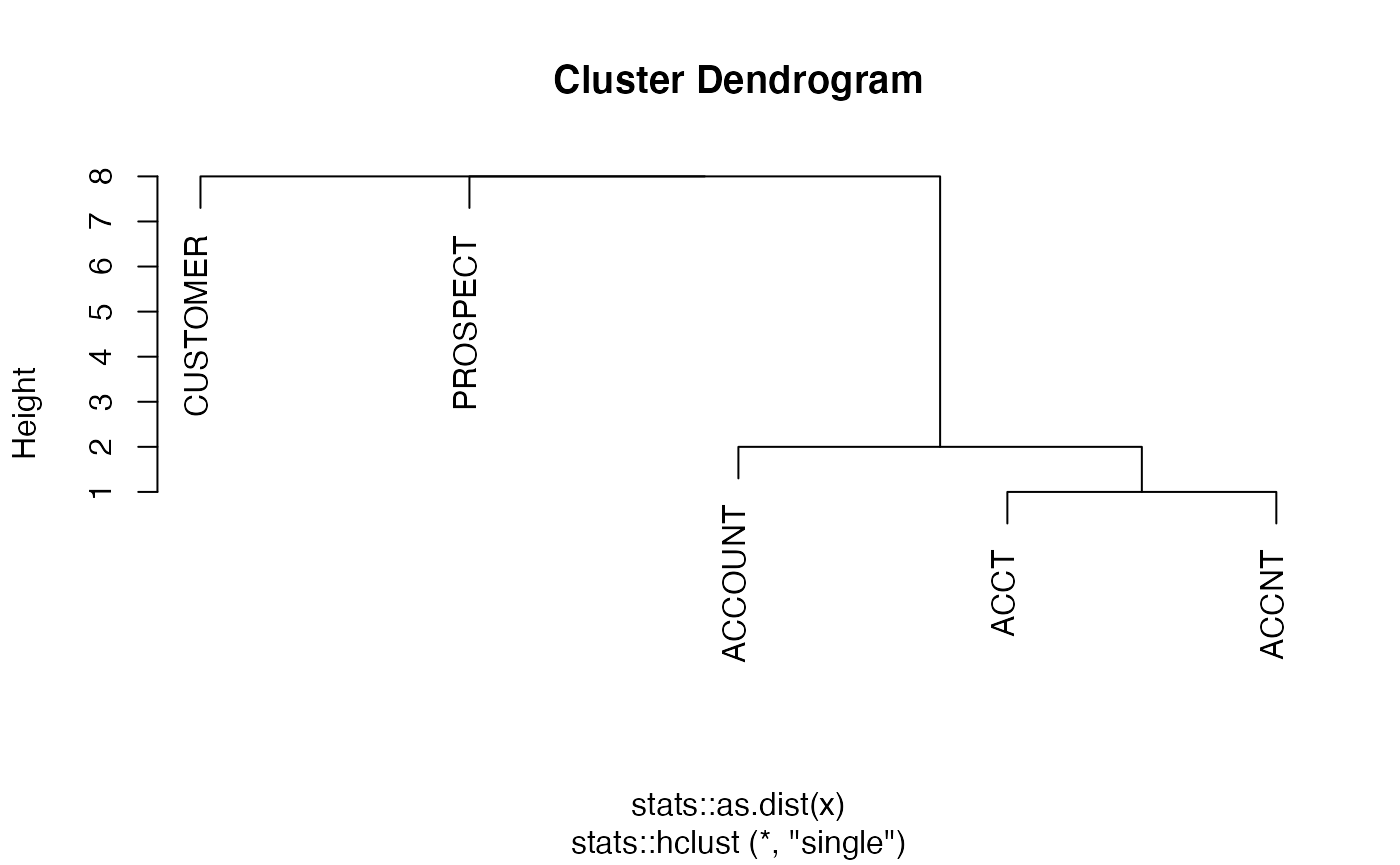
In the plots above, we can see that clustering does not help surface the problematic level 1 duplication, but it might help us notice the level 2 redundancies. Thus, this is a manual, exploratory tool but not guaranteed to highlight all problems.
From here forward, we return to using the original convo read in above for demonstration.
Evaluate & Compare
Evaluate a set of names (e.g. variable or file names) against the convo object to find violations:
col_names <- c("ID_A", "IND_A", "XYZ_D", "AMT_B", "AMT_Q", "ID_A_1234", "ID_A_12")
evaluate_convo(convo, col_names)
#> Level 1
#> - XYZ_D
#> Level 2
#> - AMT_B
#> - AMT_Q
#> Level 3
#> - ID_A_12Compare stub lists and identify new potential entries (stubs used in variables but not in controlled vocabulary):
convo_colnames <- parse_stubs(col_names)
convo_colnames
#> Level 1
#> - AMT
#> - ID
#> - IND
#> - XYZ
#> Level 2
#> - A
#> - B
#> - D
#> - Q
#> Level 3
#> - 12
#> - 1234
compare_convo(convo_colnames, convo, fx = "setdiff")
#> Level 1
#> - XYZ
#> Level 2
#> - B
#> - Q
#> Level 3
#> - 12(Note that if your names are separated by a different delimiter than _, you may pass that to parse_stubs() and most other functions shown in this demo using the sep = argument.)
If desired, newly uncovered stubs can be manually added to the convo:
convo2 <- add_convo_stub(convo, level = 2, stub = "B", desc = "Type B")
convo2
#> Level 1
#> - ID
#> - IND
#> - AMT
#> - VAL
#> - CAT
#> - CD
#> - DT
#> Level 2
#> - A
#> - C
#> - D
#> - B
#> Level 3
#> - \d{4}Or, alternatively, the compare_convo() function can accept a "union" option to merge needed new stubs between two objects:
convo_union <- compare_convo(convo_colnames, convo, fx = "union")
convo_union
#> Level 1
#> - ID
#> - AMT
#> - IND
#> - XYZ
#> - VAL
#> - CAT
#> - CD
#> - DT
#> Level 2
#> - A
#> - B
#> - D
#> - Q
#> - C
#> Level 3
#> - \d{4}
#> - 12Record
After conducting set operations on a convo as shown above, a new convo YAML specification can be written back out to YAML:
write_convo(convo_union, filename = "new-convo.yml", path = tempdir())Validate
Generate a pointblank agent for data validation:
filepath <- system.file("", "ex-convo.yml", package = "convo")
convo <- read_convo(filepath)
agent <- create_pb_agent(convo, data.frame(IND_A = 1, IND_B = 5, DT_B = as.Date("2020-01-01")))
pointblank::interrogate(agent)| Pointblank Validation | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
[2021-01-04|01:20:21]
data frame
tbl
|
|||||||||||||
| STEP | COLUMNS | VALUES | TBL | EVAL | ⋅ ⋅ ⋅ | PASS | FAIL | W | S | N | EXT | ||
| 1 | col_is_numeric()
|
— | → |
✓ |
1 |
11.00
|
00.00
|
— |
— |
— |
— |
||
| 2 | col_is_numeric()
|
— | → |
✓ |
1 |
11.00
|
00.00
|
— |
— |
— |
— |
||
| 3 | col_vals_in_set()
|
→ |
✓ |
1 |
11.00
|
00.00
|
— |
— |
— |
— |
|||
| 4 | col_vals_in_set()
|
→ |
✓ |
1 |
00.00
|
11.00
|
— |
— |
— |
||||
| 5 | col_is_date()
|
— | → |
✓ |
1 |
11.00
|
00.00
|
— |
— |
— |
— |
||
| 2021-01-04 01:20:21 UTC< 1 s2021-01-04 01:20:21 UTC | |||||||||||||
Or create a pointblank YAML file for portability:
filepath <- system.file("", "ex-convo.yml", package = "convo")
convo <- read_convo(filepath)
write_pb(convo, c("IND_A", "AMT_B"), filename = "convo-validation.yml", path = tempdir())read_fn: ~setNames(as.data.frame(matrix(1, ncol = 2)), c("IND_A", "AMT_B"))
tbl_name: .na.character
label: '[2021-01-04|01:20:23]'
locale: en
steps:
- col_is_numeric:
columns: vars(IND_A)
- col_vals_in_set:
columns: vars(IND_A)
set:
- 0.0
- 1.0
- col_is_numeric:
columns: vars(AMT_B)
- col_vals_gte:
columns: vars(AMT_B)
value: 0.0Document
Make data dictionary:
vars <- c("AMT_A_2019", "IND_C_2020")
desc_df <- describe_names(vars, convo, desc_str = "{level1} of {level2} in given year")
DT::datatable(desc_df)Visualize data as controlled vocabulary components:
vbls <- c("AMT_A_2019", "AMT_B", "AMT_C", "IND_A", "IND_B_2020")
vbls_df <- parse_df(vbls)
viz_names(vbls_df)Describe an overall convo specification:. Optionally include the “contracts” (or validation checks) in the documentation (also powered by pointblank):
desc_df <- describe_convo(convo, include_valid = TRUE, for_DT = TRUE)
DT::datatable(desc_df, escape = FALSE)Beyond Column Names
convo can manage controlled vocabularies beyond column names, as well. For example, convo can help document files is a large project.
filenames <- c("analysis/validation-a.Rmd",
"analysis/validation-b.Rmd",
"analysis/analysis.Rmd",
"analysis/report.Rmd",
"src/script-a.sql",
"src/script-b.sql")
filenames_clean <- gsub("\\.[A-Za-z]+$", "", basename(filenames))
parse_stubs(filenames_clean, sep = "-")#> Level 1
#> - analysis
#> - report
#> - script
#> - validation
#> Level 2
#> - a
#> - b