Generating Milestones & Issues from YAML
Source:vignettes/building-custom-plans.Rmd
building-custom-plans.Rmdprojmgr helps automate bulk posting of issues or
milestones to GitHub with the notion of plans and to-do lists.
Plans are a collection of milestones and issues assigned to them. In general, these issues are going to be created proactively as foreseen key steps in a project (versus the common reactive usage of GitHub issues to report bugs and request enhancements.) Plans can serve as a roadmap or framework for tackling a large chunk of work.
To-do lists are simply collections of issues. These might just be many bugs, feature enhancements, or ideas you jotted down while working offline or while not wanting to get on GitHub to log them. Alternatively, they also could be created proactively as with plans.
To reduce the manual effort of bulk creation of plans and to-do
lists, projmgr offers functionality to read, interpret, and
post milestones and issues encoded in YAML, a light-weight markup language.
Creating a Plan with YAML
YAML can be used to specify milestones and issues with all the same
fields as are accepted into post_milestone() and
post_issue(). Consider the following YAML file as an
example:
- title: Data cleaning and validation
description: >
We will conduct data quality checks,
resolve issues with data quality, and
document this process
due_on: 2018-12-31T12:59:59Z
issue:
- title: Define data quality standards
body: List out decision rules to check data quality
assignees: [emilyriederer]
labels: [a, b, c]
- title: Assess data quality
body: Use assertthat to test decision rules on dataset
labels: [low]
- title: Resolve data quality issues
body: Conduct needed research to resolve any issues
- title: Exploratory data analysis
description: >
Create basic statistics and views to better
understand dataset and relationships
issue:
- title: Summary statistics
body: Calculate summary statistics
- title: Visualizations
body: Create univariate and bivariate plotsThe read_plan() function reads plan YAML files. We will
continue to work with the example plan embedded in the package.
plan_path <- system.file("extdata", "plan.yml", package = "projmgr", mustWork = TRUE) my_plan <- read_plan(plan_path)
This function converts YAML to an R list. You can check the structure
of this output with base R str() function which shows the
structure of a list:
str(my_plan) #> List of 2 #> $ :List of 4 #> ..$ title : chr "Data cleaning and validation" #> ..$ description: chr "We will conduct data quality checks, resolve issues with data quality, and document this process\n" #> ..$ due_on : chr "2018-12-31T12:59:59Z" #> ..$ issue :List of 3 #> .. ..$ :List of 4 #> .. .. ..$ title : chr "Define data quality standards" #> .. .. ..$ body : chr "List out decision rules to check data quality" #> .. .. ..$ assignees: chr "emilyriederer" #> .. .. ..$ labels : chr [1:3] "a" "b" "c" #> .. ..$ :List of 3 #> .. .. ..$ title : chr "Assess data quality" #> .. .. ..$ body : chr "Use assertthat to test decision rules on dataset" #> .. .. ..$ labels: chr "low" #> .. ..$ :List of 2 #> .. .. ..$ title: chr "Resolve data quality issues" #> .. .. ..$ body : chr "Conduct needed research to resolve any issues" #> $ :List of 3 #> ..$ title : chr "Exploratory data analysis" #> ..$ description: chr "Create basic statistics and views to better understand dataset and relationships\n" #> ..$ issue :List of 2 #> .. ..$ :List of 2 #> .. .. ..$ title: chr "Summary statistics" #> .. .. ..$ body : chr "Calculate summary statistics" #> .. ..$ :List of 2 #> .. .. ..$ title: chr "Visualizations" #> .. .. ..$ body : chr "Create univariate and bivariate plots" #> - attr(*, "class")= chr [1:2] "plan" "list"
Alternatively, you may print() out the plan for a more
aesthetic rpresentation:
print(my_plan) #> Plan: #> 1. Data cleaning and validation (3 issues) #> 2. Exploratory data analysis (2 issues)
Finally, this collection of milestones and associated issues can be
posted to GitHub with the post_plan() function.
experigit <- create_repo_ref("emilyriederer", "experigit") post_plan(experigit, my_plan)
The result of this command would be the creation of two milestones
created in the experigit repo. The first has three issues
and the second has two issues.
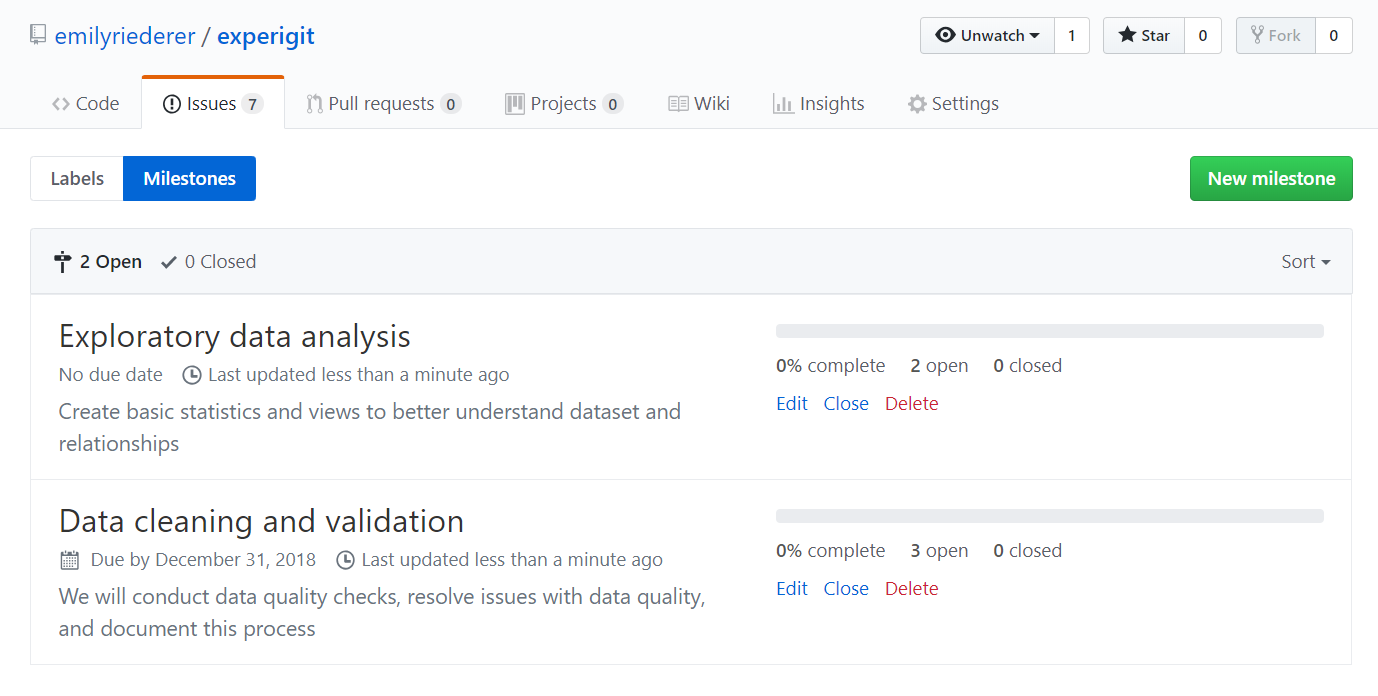
Milestones posted on GitHub
Note that you can also pass in YAML directly as a character string:
plan_yaml_vbl <- " milestone1: title: First draft body: Complete the first draft of this paper for review milestone2: title: Make revisions body: Repsond to feedback from reviewers " plan_from_vbl <- read_plan(plan_yaml_vbl) str(plan_from_vbl) #> List of 2 #> $ milestone1:List of 2 #> ..$ title: chr "First draft" #> ..$ body : chr "Complete the first draft of this paper for review" #> $ milestone2:List of 2 #> ..$ title: chr "Make revisions" #> ..$ body : chr "Repsond to feedback from reviewers" #> - attr(*, "class")= chr [1:2] "plan" "list"
TO recall the precise YAML formatting required, the
template_yaml() function prints an example to your
console:
template_yaml("plan") #> - title: Enter a short, informative title of your goal #> description: > #> Enter a longer description of the objectives #> due_on: 2018-12-31T12:59:59Z #> issue: #> - title: Title of task 1 to complete #> body: Describe this step #> assignees: [emilyriederer] #> labels: [a, b, c] #> - title: Title of task 2 to complete #> body: Describe this step #> labels: [low] #> #> - title: Enter another short, informative title of your goal #> description: > #> Enter a longer description of the objectives #> issue: #> - title: Title of task 1 to complete for step 2 #> body: Describe this step #> - title: Title of task 2 to complete for step 2 #> body: Describe this step
Create a To-Do List with YAML
The workflow for posting to-do lists is very similar to that of plans. Consider the following YAML file as an example:
- title: Consider renaming my_very_long_function_name
body: >
This name is unneccesarily long and hence
it is very hard and annoying to type
assignees: [emilyriederer]
labels: [low]
- title: Make sure documentation links right pages of API docsSimilarly, the read_todo() function reads in a to-do
YAML file and converts it to an R list:
todo_path <- system.file("extdata", "todo.yml", package = "projmgr", mustWork = TRUE) my_todo <- read_todo(todo_path) str(my_todo) #> List of 2 #> $ :List of 4 #> ..$ title : chr "Consider renaming my_very_long_function_name" #> ..$ body : chr "This name is unneccesarily long and hence\n it is very hard and annoying to type\n" #> ..$ assignees: chr "emilyriederer" #> ..$ labels : chr "low" #> $ :List of 1 #> ..$ title: chr "Make sure documentation links right pages of API docs" #> - attr(*, "class")= chr [1:2] "todo" "list"
This collection of issues can be posted to a GitHub with the
post_todo() function.
experigit <- create_repo_ref("emilyriederer", "experigit") post_todo(experigit, my_todo)
Just like with plans, you can also pass a character string instead of
a file and use template_yaml() to remind yourself of the
required format:
template_yaml("todo") #> - title: Informative title #> body: > #> Longer description of issue #> assignees: [emilyriederer] #> labels: [low] #> #> - title: Another informative title - body not required!
Reporting on Plans or To-Do Lists
Sometimes, it may be helpful to share what you plan to do with a
larger team. The report_plan() and
report_todo() functions translates plans and to-do lists
into HTML for inclusion in RMarkdown.
For example:
report_plan(my_plan)
- ☐ Define data quality standards
- ☐ Assess data quality
- ☐ Resolve data quality issues
- ☐ Summary statistics
- ☐ Visualizations
report_todo(my_todo)
To Do ( 0 / 2 )
- ☐ Consider renaming my_very_long_function_name
- ☐ Make sure documentation links right pages of API docs
These plans looks thematically similar to the output of
report_progress() for consistency in reporting of planned
or in-progress work. The (0 / {Number of issues})
information is provided by default, for consistency with the
report_progress() function. However, this can also be
disabled by settings show_ratio = FALSE for a cleaner and
less distracting look.
report_plan(my_plan, show_ratio = FALSE)
- ☐ Define data quality standards
- ☐ Assess data quality
- ☐ Resolve data quality issues
- ☐ Summary statistics
- ☐ Visualizations
report_todo(my_todo, show_ratio = FALSE)
To Do
- ☐ Consider renaming my_very_long_function_name
- ☐ Make sure documentation links right pages of API docs
Create a Plan or To-Do List with R
Of course, projmgr’s YAML-parsing functionalities are
only provided as a convenience. Users are also welcome to create their
own plans and to-do lists simply with base R’s list()
function. For example, the following code creates an analog to the
second milestone in the YAML above.
milestone <- list( title = "Exporatory data analysis", description = "Create basic statistics and views", issue = list( list(title = "Summary statistics", body = "Calculate summary statistics"), list(title = "Visualizations", body = "Create univariate and bivariate plots") ) ) plan <- list(milestone) str(plan) #> List of 1 #> $ :List of 3 #> ..$ title : chr "Exporatory data analysis" #> ..$ description: chr "Create basic statistics and views" #> ..$ issue :List of 2 #> .. ..$ :List of 2 #> .. .. ..$ title: chr "Summary statistics" #> .. .. ..$ body : chr "Calculate summary statistics" #> .. ..$ :List of 2 #> .. .. ..$ title: chr "Visualizations" #> .. .. ..$ body : chr "Create univariate and bivariate plots"
To take full advantage of some features (like the plan-specific
print method), the only additional step you need to take is
manually adding "plan" or "todo" to the
class of the variable you have created.